In the days before the Internet, computer game reviews were written in dead-tree magazines. Naturally, magazines had to go to press a few weeks or so before they would appear in shops. So if a game was to be released for Christmas to cash in on season sales, the game had to be reviewed in magazines that were in the shops earlier in December. This may very well have meant that the game had to be sent to magazines to be reviewed as early as October or November. Game development, like most other sorts of software development, tends to go on until the very last moment. So what happened if a game wasn’t quite finished when it was time for reviews? Simple, hand the magazines an incomplete version!
Amiga Power reviewed Super Stardust in October 1994, long before any other magazines got to try it. Four yellow headers appear throughout the review. When rearranged, they spell out:

Quite why they left such an obvious clue to the fact that the reviewed game only contained three of five levels is a good question, perhaps to tease other magazines since they beat them to a review by several months.
Sensible World of Soccer fared similarly. Amiga Magazine Rack – a website dedicated to scans of old Amiga magazines, and general keeper of knowledge – tells the story:
The biggest reader backlash in Amiga Power’s history was due to reviewing the unfinished game Sensible World Of Soccer in AP44. It was awarded 95% and declared “The best Amiga game ever.”
A flood of complaints rolled in regarding bugs in the game. AP came clean regarding the review and invited Sensible Software to address the complaints. Chris Chapman and Jon Hare answered the criticisms, which Stuart Campbell in his role as Sensible’s Development manager assembled into an amusing column called “Swiz” in AP48 on pages 24-26.
It was unfortunate that the answers were made funny as they left Sensible Software looking arrogant, with a majority of the responses along the lines of “we had to rush it out to cash in on the Christmas market” or abusing the original reader.
Working on a project related to the early 90’s racing game Formula One Grand Prix made me read a few old reviews of the Amiga version on Amiga Magazine Rack for nostalgia’s sake. However, looking at the screenshots featured in the reviews, I noticed something out of place. When released, the game featured cars and tracks from the 1991 F1 season, but it was obvious from some screenshots that the version of the game that they had reviewed actually included cars from the 1990 season. Also, some reviews featured images with a cockpit that was quite different from the one in the released version.
Since the dates of the reviews vary from October 1991 to March 1992, and the game was released in January 1992, it seems obvious to draw the conclusion that most magazines received versions that were somewhat less complete than others.
I looked at nine different reviews (the ones that had scanned pages on Amiga Magazine Rack). One review was from October 1991, four of them from November, one from December, two from January 1992 and one from March. Of these nine reviews, only one featured the cars from the version that was actually released. Not surprisingly, it’s the March review in Amiga Action, appearing two months later than any other review.
We can start off with a major give-away: The Amiga Power review from November 1991 even features the words “based on statistics from the 1990 season”. So that makes it pretty obvious that the game was originally supposed to contain the 1990 season, and that the reason they changed it was that the whole of 1991 had actually passed.
Let’s look at some oddities in detail…
First of all, the cockpits, shown below for comparison. The one on the right is the released version, containing much more information about speed, number of cars, laps, information about which driver aids are active, etc. The one on the left – which is featured in many of the reviews – seems barren by comparison, just lap times, oil and fuel lights – but it does include a gear lever!
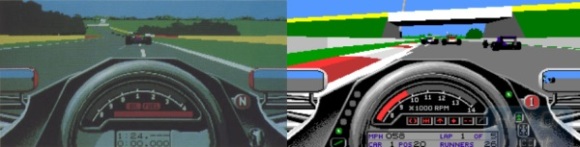
Seeing as the one on the right is actually more useful, it’s good to know that when it came to cockpits they didn’t remove features as time wore on, but actually added them.
Moving on, the review in Amiga Action from December 1991 features a multitude of weirdness. It has the correct instruments, but the cars are from 1990. However, it has in-game screenshots featuring drivers Pierluige [sic] Martini and Eric van de poele [sic]. That Pierluigi Martini is spelled incorrectly is almost forgivable. However, Eric van de Poele did not even race in F1 in 1990. And more interestingly: the released version of the game did not feature the names of any real F1 drivers or teams. These were supplied on a piece of paper in the game box, for the user to enter on their own.
There are lots of other examples in the reviews of cars from 1990 instead of 1991.

On the left is an in-game screenshot of a car from one of the reviews. In the middle is an actual Benetton car from 1990, and on the right is one from 1991. Which of these does the in-game car resemble the most?
The Amiga Power review also mentions a feature that didn’t make it into the game: “Sparks fly from the cars just like the ones you see in the racing on TV”. Eh, no, the released game had no such feature.
A couple of the reviews also mention a feature where there is a TV presenter who talks about your exploits after each race.

Sounds like it could have been an interesting feature, a shame that it didn’t make it to the final game.
A final note of disorientation: The released game has the colours of at least three teams wrong. First of all, the Tyrrell cars were dark grey in real-life whereas the the game has them painted dark blue. A team that actually was dark blue, Lamborghini’s Modena Team, features the gray-blue-white colours of the single-car Coloni entry. The Coloni on the other hand is all-yellow with blue wings. No team in 1991 had this colour scheme, but Coloni ran an all-yellow car (with black wings) in – you guessed it – 1990.
There are other things – both in the reviews and in the finished game – that are a bit wacky, but there has to be a limit to the madness (and this blog post). All in all, much confusion, but all the more merriment.